
People in 2022 take advantage of artificial intelligence on a daily basis thanks to apps like Uber, Google Maps, and music recommendation algorithms. Deep learning, machine learning, and artificial intelligence are all used interchangeably, but this mistake persists. Are artificial intelligence and machine learning the same thing? is a frequent Google search query.

Let’s be clear: deep learning (DL), machine learning (ML), and artificial intelligence (AI) are all three distinct concepts.
Artificial intelligence: Like mathematics or biology, artificial intelligence is a scientific field. It researches how to create intelligent systems and robots that can think critically and creatively to solve issues, something that has long been seen as a human right.
Machine learning : Artificial intelligence (AI) is a subset that gives systems the capacity to autonomously learn from experience and advance without being explicitly designed. Different algorithms, such as neural networks, are used in machine learning to assist with issue solving.
Deep learning, also known as deep neural learning, is a branch of machine learning that uses neural networks to assess many variables in a way that is comparable to the structure of the human neural system.
This is how it looks on an Euler diagram:
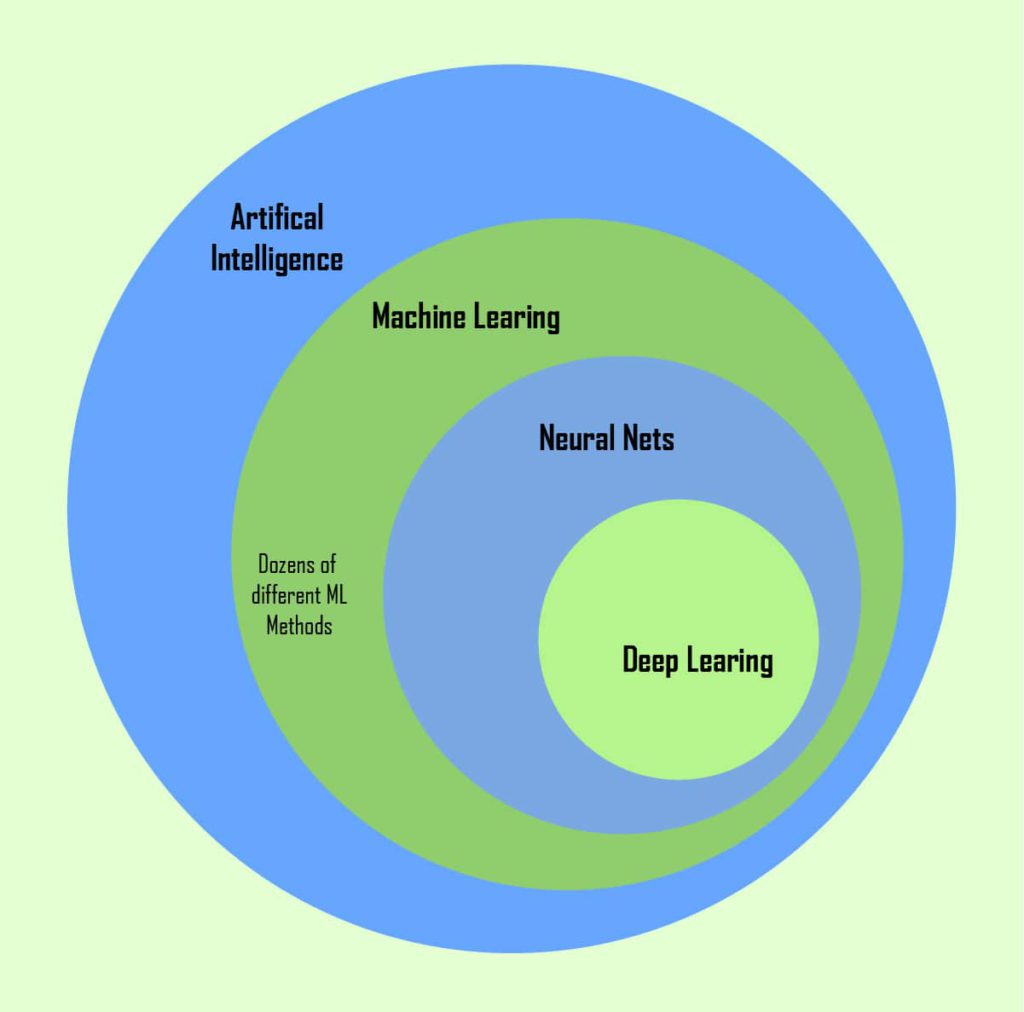
3 faces of artificial intelligence
At a computer science symposium in Dartmouth in 1956, the phrase “artificial intelligence” was first used. The term “AI” was used to denote an effort to simulate how the human brain functions in order to build more sophisticated computers. The experts anticipated that it shouldn’t take very long to comprehend how the human mind functions and to digitalize it. After all, the conference brought together some of the most innovative thinkers of the era for a marathon two-month brainstorming session.
The researchers had a great time in Dartmouth that summer, but the findings were quite depressing. Programming the brain to mimic it turned out to be… challenging.
Nevertheless, certain outcomes were attained. For instance, the researchers realised that learning (to cope with dynamic and unpredictable surroundings), natural language processing (for human-machine contact), and creativity (to free humanity from many of its problems) are essential components of an intelligent computer.
Even in this day and age, when artificial intelligence is pervasive, the computer is still far from perfectly simulating human intelligence.
AI is generally divided into 3 categories:
Narrow/Weak AI
It is helpful to compare weak AI to strong AI in order to comprehend what weak AI is. The objectives of these two AI systems are distinct.
Artificial humans, or “strong” AI, are intended to be machines that possess all of our mental faculties, including perceptual consciousness. On the other hand, “weak” AI aims to create data-processing units that have what appears to be the entire mental toolkit of human beings. Searle (1997)
Weak, or narrow, AI excels in a single activity but falls short of humans in all other contexts outside of those which fall within its purview.
You’ve surely heard about Deep Blue, the first chess player-defeating computer. Garry Kasparov in 1996; not just any anyone. About 200 million chess positions per second might be generated and evaluated by Deep Blue. To be completely honest, some did not consider it to be AI in the truest sense, while others considered it to be one of the early instances of subpar AI.
AlphaGo is a well-known illustration of how AI can outperform humans in games. Because it learned how to play the game rather than just calculating all the movements, this program was successful in one of the most challenging games ever created (which is impossible).
Nowadays, research, industry, and the medical field all make extensive use of limited artificial intelligence. For instance, a business called DOMO announced the release of Mr. Roboto in 2017. This AI software system’s robust analytics features can offer business owners suggestions and insights for the growth of their operations. It has the ability to identify anomalies and patterns that can help with risk assessment and creative planning. Similar initiatives exist for other sectors as well, and major corporations like Google and Amazon participate in their growth.
General/strong AI
In the near future, machines will resemble humans at this point. They learn independently and make their own decisions. They are not only capable of solving logical problems, but they also experience emotions.
How do you create a living machine, exactly? The computer can be programmed to respond to inputs with certain emotive vocal reactions. Virtual assistants and chatbots are already extremely adept at keeping up a conversation. Additionally, studies to train robots to recognise human emotions are currently underway. But does re-creating emotional responses actually make the machines emotionally human?
Superintelligence
Everyone typically anticipates reading something like this while reading about AI. Machines are far ahead of people. Intelligent, perceptive, imaginative, and very good with people. Either it will improve human life or it will end all human life.
The sadness is that modern scientists would never even consider building autonomous emotional robots similar to the Bicentennial Man. Except maybe for this guy who built a robot version of himself.
Currently, data scientists are concentrating on the following tasks, which can contribute to the development of general and superintelligence:
Machine Reasoning: MR systems have access to a variety of information, such a library or a database. Based on this data, they can develop some insightful theories using deduction and induction approaches. Planning, data representation, search, and optimization for AI systems are few examples;
Robotics: This scientific discipline focuses on creating, developing, and managing robots, ranging from intelligent androids to roombas;
Machine Learning: The study of computer models and algorithms used by machines to carry out certain tasks is referred to as machine learning.
You could refer to them as AI creation techniques. You can utilise only one or merge them all into a single system. Let’s now delve into the specifics more.
How can machines learn?
A branch of artificial intelligence (AI) called machine learning “focuses on teaching computers how to learn without the need to be programmed for specific tasks,” according to its definition. The fundamental principle of machine learning is that it is feasible to develop algorithms that can learn from data and make predictions about it.
These 3 elements are necessary to “teach” the machine:
Datasets. Datasets are specific collections of samples used to train machine learning algorithms. The samples may be composed of text, numbers, graphics, or other types of data. A quality dataset typically requires a lot of time and work to produce.
Features. Features are significant pieces of information that are essential to the task’s resolution. They instruct the machine on what to focus on. How are the features chosen? Let’s imagine you want to estimate how much an apartment will cost. It is challenging to use linear regression to estimate, for instance, how much a location may cost depending on the sum of its length and width. However, it is considerably simpler to establish a link between building price and its location.
In the case of supervised learning, when you have training data with labelled data, which contain the “correct solutions,” and a validation set, it operates as described above (we will discuss supervised and unsupervised ML later on). The programme learns how to arrive at the “correct” solution throughout the learning process. After that, hyperparameters are tuned using the validation set to prevent overfitting. Unsupervised learning, on the other hand, uses unlabeled input data to learn features. The machine learns to recognise patterns on its own; you do not have to instruct it where to look.
Algorithm. The same problem can be solved using many algorithms. The accuracy or speed of getting the results can vary depending on the algorithm. As with ensemble learning, there are situations when combining several algorithms will result in improved performance.
Any software that employs machine learning is more independent than coded instructions manually for carrying out particular tasks. The system gains the ability to spot trends and offer insightful forecasts. An ML-powered system can become more adept at a given task than humans if the dataset quality was excellent and the features were carefully picked.
Deep Learning
A group of machine learning algorithms called “deep learning” were modelled after the way the human brain is organised. Deep learning techniques make use of intricate, multi-layered neural networks, where non-linear modifications of the input data steadily raise the level of abstraction.
Information is passed from one layer to another in a neural network across connecting channels. Because each of them has a value associated with it, they are referred to as weighted channels.
Every neuron has a distinct value known as bias. The weighted sum of the inputs that are received by the neuron are then multiplied by this bias, and an activation function is then applied. If the neuron is triggered, it depends on the outcome of the function. Each excited neuron transmits information to the layers below it. Up until the second-to-last layer, this continues. The final layer that generates outputs for the programme is the output layer in an artificial neural network.
A data scientist requires a tonne of training data to be able to train these neural networks. This is because many different factors must be taken into account for the solution to be accurate.
Although deep learning algorithms are currently quite popular, there isn’t a clear line separating them from less-deep algorithms.
For instance, speech recognition programmes like Google Assistant and Amazon Alexa are some real-world uses for DL. The speaker’s sound waves can be visualised as a spectrogram, which is a time-stamp of several frequencies. Such sequences of spatial-temporal input signals can be recognised and processed by a neural network with the ability to retain sequence inputs (such as LSTM, short for long-short-term memory). It develops a word-to-spectrogram mapping as it learns.
DL is very similar to what most people picture when they hear the term “artificial intelligence.” That a computer can learn on its own is amazing! Unfortunately, DP algorithms are not perfect. But because it can be used for a wide range of tasks, DL is a favourite among programmers. We’re going to talk about some additional ML methods right now, though.
No Free Lunch and why there are so many ML algorithms
Before we start: You are free to stick with the classification scheme you want from the various options for the algorithms.
The No Free Lunch Theorem is a fundamental tenet in artificial intelligence research. It asserts that there is no ideal algorithm that performs flawlessly on every task, including natural voice recognition and surviving in the wild. Consequently, a range of tools are required.
Algorithms can be categorised based on how they learn or how similar they are. Because it is more logical for a beginner to look at the algorithms categorised according to their learning approach in this post.
4 Groups of ML algorithms
Therefore, machine learning algorithms are typically split into 4 classes based on how they learn:
Supervised Learning
There is a training set with labelled data, and the training process is “supervised,” meaning a teacher assists the programme at all times. For instance, you might wish to instruct the computer to separate the baskets for red, blue, and green socks.
You must first demonstrate each thing to the system and identify each one. Run the programme after that on a validation set to see if the learned function was accurate. When the program’s conclusions are incorrect, the programmer corrects the programme. The training procedure is carried out repeatedly until the model’s accuracy on the training data reaches the target level. Regression and classification frequently employ this kind of learning.
Algorithm examples:
- Naive Bayes,
- Support Vector Machine,
- Decision Tree,
- K-Nearest Neighbours,
- Logistic Regression,
- Linear and Polynomial regressions.
Used for: search and categorization, language identification, spam filtering, and computer vision.
Unsupervised Learning
In unsupervised learning, you don’t provide the software any features so it can look for patterns on its own. Consider that the computer is required to sort your large basket of laundry into different piles for socks, T-shirts, and pants. Unsupervised learning is frequently used to cluster data into groups based on similarities.
Insightful data analytics can also benefit from unsupervised learning. The incapacity of humans to process enormous volumes of numerical data causes us to occasionally miss patterns that the programme can spot. To identify fraudulent transactions, estimate sales and discounts, or analyse client preferences based on search history, for instance, UL can be utilised. Although the programmer is not sure what they are looking for, the system can undoubtedly spot some trends.
Algorithm examples:
- K-means clustering,
- DBSCAN,
- Mean-Shift,
- Singular Value Decomposition (SVD),
- Principal Component Analysis (PCA),
- Latent Dirichlet allocation (LDA),
- Latent Semantic Analysis, FP-growth.
Data segmentation, anomaly detection, recommendation engines, risk management, and fake image analysis are all uses for this.
Semi-supervised Learning
As you might infer from the title, semi-supervised learning uses a combination of labelled and unlabeled samples as its input data.
Although the model must uncover patterns on its own to organise the data and generate predictions, the programmer has a particular prediction outcome in mind.
Reinforcement Learning
Trial and error is how humans learn, and this is extremely similar. Humans don’t require constant supervision like in supervised learning in order to learn well. We still learn quite well even when we just get reinforcement signals in response to good or negative acts. For instance, a young toddler who experiences discomfort learns not to touch a hot pan.
The freedom from training on static datasets that reinforcement learning offers is one of its most appealing features. Instead, the machine may learn in dynamic, noisy settings like the real world or game worlds.
Because they offer the best surroundings for environments rich in data, games are highly helpful for research on reinforcement learning. Games’ scores make excellent reward cues for teaching behaviours that are driven by rewards, like Mario.
Algorithm examples:
- Q-Learning,
- Genetic algorithm,
- SARSA,
- DQN,
- A3C.
Used for: resource management, gaming, robots, and self-driving cars.
Conclusion:
Numerous fantastic uses of artificial intelligence are revolutionising the field of technology. While developing an AI system that is typically on par with humans is still a pipe dream, machine learning (ML) now enables the computer to execute calculations, pattern recognition, and anomaly detection better than we can.

